Building a Distributed Job Scheduler from Scratch (Part 2)
A multipart hands on series about building a distributed job scheduler from scratch.

Recap
Welcome back to the second part of our tutorial series on building a distributed job scheduler! In our previous installment, we laid the foundation by defining the functional and non-functional requirements of our job scheduler. Now, it's time to dive into the heart of our system by designing a durable storage system to store job details effectively. If you're a software engineer eager to learn new technologies, this tutorial is tailored just for you.
Modeling Job Class
Since we have already figured out what are the various Job types and the ways to configure callbacks, our actual job has become quite easier.
public abstract class Job implements Serializable {
String id;
// The actual HTTP url where callback will be made.
String callbackUrl;
int successStatusCode;
long relevancyWindow;
// Defines the maximum window for callback execution
TimeUnit relevancyWindowTimeUnit;
}
public class ExactlyOnceJob extends Job {
LocalDateTime dateTime;
}
public class RecurringJob extends Job {
List<LocalDateTime> dateTimes;
}
public class RepeatedJob extends Job {
LocalDateTime startTime;
LocalDateTime endTime;
TimeUnit repeatIntervalTimeUnit;
long repeatInterval;
}
SQL vs NoSQL
Before figuring out the database, let's figure out the query patterns.
Store job details - We need high write throughput to store structured data. Additionally, we must be prepared for possible schema changes in the future.
Get job details provided an ID - High read throughput to get details of a job based on a key.
No transaction guarantees are required.
No range scans are required.
Considering these requirements, we can choose a NoSQL database like Cassandra or HBase. For this tutorial, we'll leverage Apache HBase due to its capabilities.
Hello, HBase!
If you are new to the world of HBase, I would recommend you to read this crisp and excellent article which would give you a fair idea of the HBase data model.
Installing HBase is a 5-minute affair and can be completed relatively easily. Just go through this link.
Now it's time to write some boilerplate utility code to interact with our newly created HBase Server.
public class HBaseManager {
private Admin admin;
private Connection connection;
public HBaseManager() throws IOException {
Configuration config = HBaseConfiguration.create();
String path = Objects.requireNonNull(this.getClass().getClassLoader().getResource("hbase-site.xml"))
.getPath();
config.addResource(new Path(path));
HBaseAdmin.available(config);
connection = ConnectionFactory.createConnection(config);
admin = connection.getAdmin();
}
public boolean tableExists(String name) throws IOException {
TableName table = TableName.valueOf(name);
return admin.tableExists(table);
}
public void createTable(String name, String columnFamily) throws IOException {
if (!tableExists(name)) {
TableName table = TableName.valueOf(name);
HTableDescriptor descriptor = new HTableDescriptor(table);
descriptor.addFamily(new HColumnDescriptor(columnFamily));
admin.createTable(descriptor);
}
}
public Table getTable(String name) throws IOException {
TableName tableName = TableName.valueOf(name);
return connection.getTable(tableName);
}
public void put(Table table, Put value) throws IOException {
table.put(value);
}
public Result get(Table table, String id) throws IOException {
Get key = new Get(Bytes.toBytes(id));
return table.get(key);
}
}
Now that our utility code is in place, we can proceed to create a Data Access Object (DAO) layer responsible for storing and retrieving job details.
public class JobDAO {
HBaseManager hBaseManager;
String columnFamily = "cf";
String data = "data";
String tableName = "jobDetails";
Table table;
public JobDAO() throws IOException {
hBaseManager = new HBaseManager();
hBaseManager.createTable(tableName, columnFamily);
table = hBaseManager.getTable(tableName);
}
public void registerJob(Job job) throws IOException {
byte[] row = Bytes.toBytes(job.getId());
Put put = new Put(row);
put.addColumn(columnFamily.getBytes(), data.getBytes(), SerializationUtils.serialize(job));
hBaseManager.put(table, put);
}
public Job getJobDetails(String id) throws IOException {
Result result = hBaseManager.get(table, id);
byte[] value = result.getValue(columnFamily.getBytes(), data.getBytes());
Job job = (Job) SerializationUtils.deserialize(value);
return job;
}
}
To ensure the functionality of our system, we'll rely on JUnit tests to validate our code. This step is crucial to confirm that our storage system works as expected.
public class JobDAOTest {
@Test
public void testRegisterJob() throws IOException {
JobDAO jobDAO = new JobDAO();
String id = UUID.randomUUID().toString();
ExactlyOnceJob exactlyOnceJob = ExactlyOnceJob.builder()
.id(id)
.callbackUrl("http://localhost:8080/test")
.successStatusCode(500)
.build();
Assertions.assertDoesNotThrow(() -> jobDAO.registerJob(exactlyOnceJob));
ExactlyOnceJob job = (ExactlyOnceJob) jobDAO.getJobDetails(id);
Assertions.assertTrue(exactlyOnceJob.equals(job));
}
}
Appendix
Project Structure
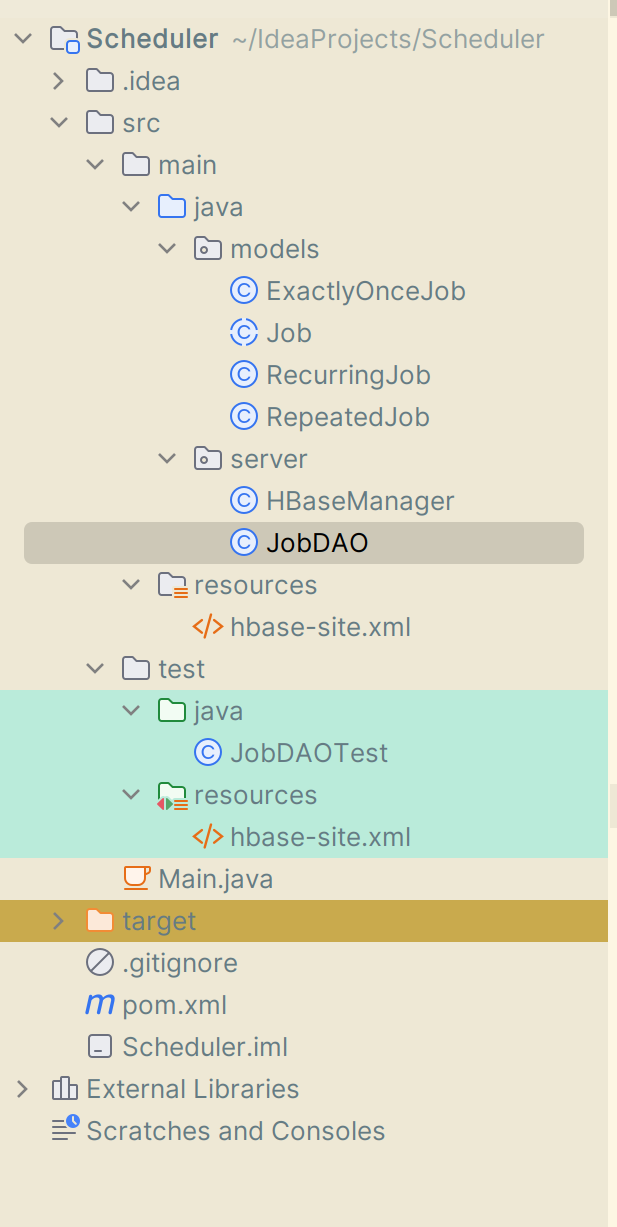
Maven pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.scheduler</groupId>
<artifactId>scheduler</artifactId>
<version>1</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.5.3</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>2.5.3</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.28</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.2.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-runner</artifactId>
<version>1.2.0</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
Conclusion
Congratulations! In this second part of our tutorial series, we've made significant progress. We've chosen a suitable database (HBase), implemented the necessary code, and validated it through test cases. But the journey doesn't end here. In the next installment, which we'll cover in part 3, we'll delve into modeling repeated jobs. Do take a pause and think about why they need to be modeled separately. Stay tuned for more exciting insights!