Ensuring Exactly-Once execution at scale in Stateful Distributed Systems
Why Exactly-Once Implementation Isn’t Straightforward

Problem Statement
You have a task and a list of application instances that can execute it. After the task is completed, they must update the database with the result. How can we ensure that only one instance executes the task? We should focus on exactly-once execution of the task because each time the task runs it can have a side-effect — it might create a file, insert a row in the database, or perform an action that should happen only once.
Let's look at some of the options that are available to us.
Leader election
Perform a leader election amongst the instances using a consensus algorithm (e.g. Zookeeper or etcd) and let the leader execute the task.
Lock based Approach
Any instance can choose the task, but before executing it, a distributed lock must be obtained using a unique ID with an external system (e.g., Zookeeper, Redis, or Aerospike). If an instance gets the lock, no other instance has it, making it safe to execute the task. The other instances will either proceed to the next available task or wait a random amount of time before trying again to get the lock on the same task.
So you think you are done?

Gotchas
Let's dissect the edge cases with our previous approaches
Leader Election
Performing leader election using a consistent core approach, like Zookeeper, can still have edge cases during network partitions.
Imagine that initially, an instance named Alice was chosen as the leader. Due to a network issue or a GC pause, Alice was disconnected from the Zookeeper cluster long enough for the cluster to promote another instance, Bob, as the leader.
Bob picks up the same task and decides to execute it. However, Alice, the previous leader, is still active and decides to execute the same task, resulting in the task being executed twice.
Optimistic Approach
If the instance having the lock dies (Alice), no other instance can pick up the task. This can be solved by having a TTL (lease period) associated with the lock.
Choosing a TTL means the job must be completed within that time frame. If the TTL is too short, the lock might expire before the task is finished. If the TTL is too long, it takes more time to recover when an instance fails. For example, if Alice goes down, no other instance can get the lock until the lease expires.
There is still a possible issue where Alice thinks it has the lock, but its lease has expired and another instance, Bob, has taken the lock. This can occur if Alice is delayed by external factors (like GC pauses or page swaps) and its lease expires. When Alice resumes, it still believes it holds the lock and proceeds to execute the task.
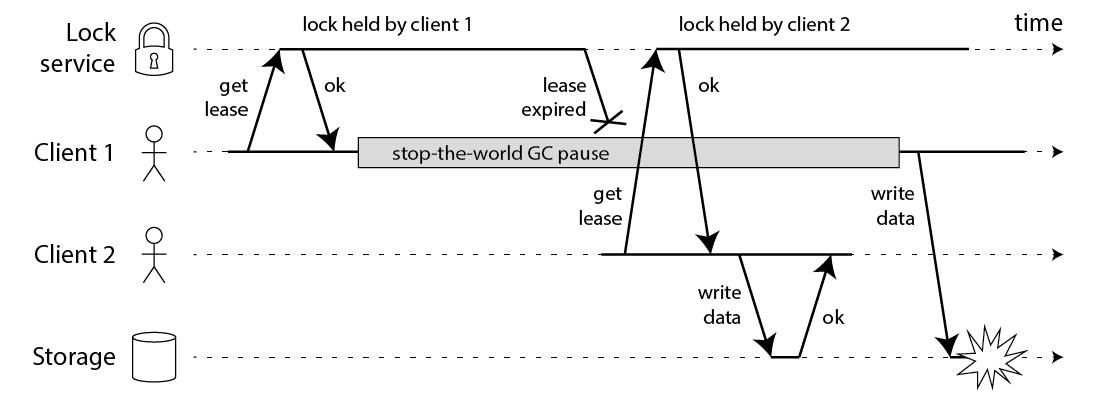
Based on the above examples, it's evident that we need another guardrail that can prevent a task from being executed twice.

Solution?
The problem with our earlier methods was the absence of safeguards during task execution. While a task was running, there were no checks to make sure it was safe to proceed.
What could some of these safeguards be?
Idempotency / Unique Key
If the side effect introduced during task execution has an idempotency or unique key associated with it, it becomes easier to detect whether something has already happened or is currently being executed.
If only the life were so simple.
Sometimes, it's not possible to have a unique key linked to the side effect. Why? Because it might be intentional. For example, in an HBase Cluster, the HBase master is in charge of assigning regions to a region server. If the HBase master believes a Region Server is down, it assigns that region (shard) to a new Region Server. Clients check the Region assignment mapping and redirect their read/write requests to the correct Region Server. Everything works fine as long as there is only one HBase master. In a split-brain scenario or network partitioning, two nodes might both think they are the Master and could perform Region reassignment tasks. This can severely affect data consistency. In this case, it's hard to assign a unique key to the region assignment task.

Fencing to the Rescue
Fencing is the process of isolating a cluster node or protecting shared resources when a node seems to be malfunctioning.
Previously, we relied on clients to behave correctly, assuming they wouldn't issue tasks unless they were the leaders. However, this assumption led to many edge cases in our design. To address this, we should add a check during task execution. Before running the task, the task execution service itself must verify if the caller has the authority to perform it.
How do we check this? The caller will provide a token that can be validated against the latest issued token (strong consistency) or the most recent token seen by the storage engine so far (linearizable reads/weak consistency).
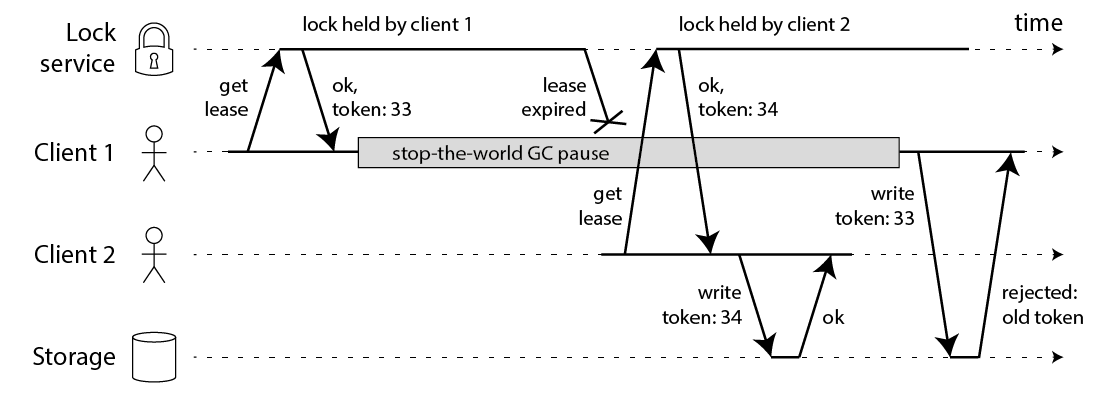
Let’s look at some practical examples which will help understand this concept as it can get quite tricky.
Split Brain Issue in Kafka Cluster
In a Kafka Cluster, there are multiple brokers — of which a single broker is selected as the controller of the entire cluster. Kafka uses Zookeeper as the consensus core. (It has now moved to Raft, but the fundamentals remain the same)
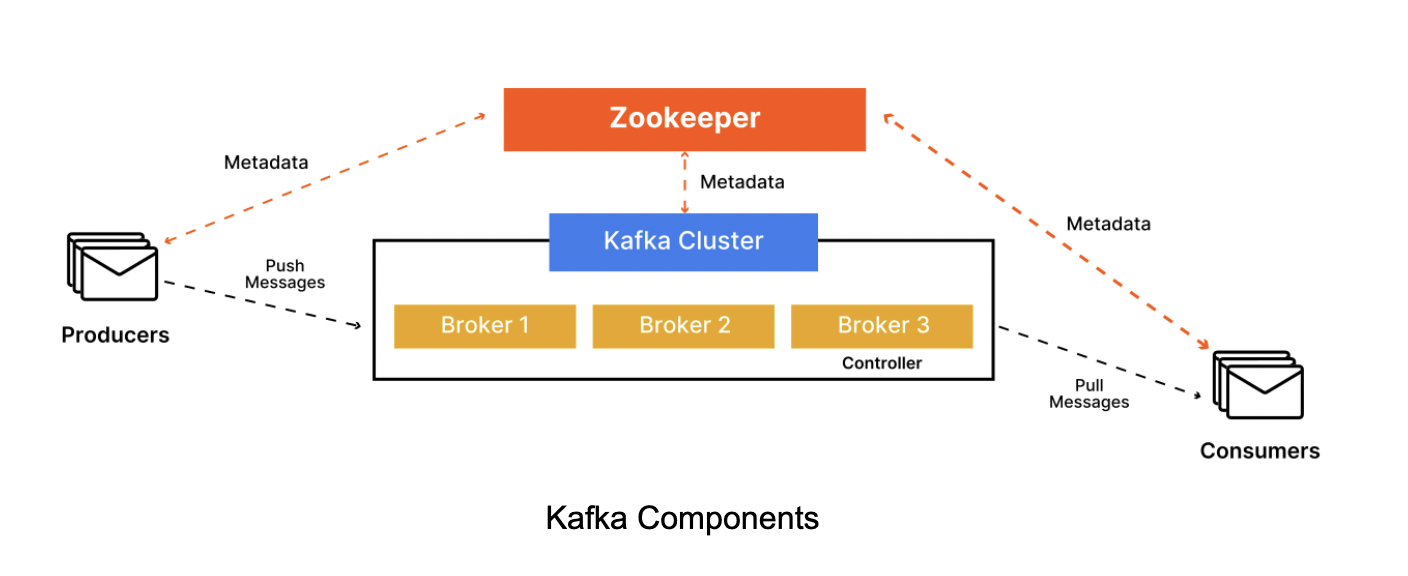
What will happen if a Controller broker dies. One of the remaining brokers must get promoted as the Controller.
Keep in mind that you cannot truly know whether a broker has stopped for good or has experienced an intermittent failure. Nevertheless, the cluster has to move on and pick a new controller. This can lead to a zombie controller. A zombie controller can be defined as a controller node which had been deemed dead by the cluster and has come back online. Another broker has taken its place but the zombie controller might not know that yet.
This can easily happen. For example, if a nasty intermittent network partition happens or a controller has a long enough stop-the-world GC pause — the cluster will think it has died and pick a new controller. In the GC scenario, nothing has changed through the eyes of the original controller. The broker does not even know it was paused, much less that the cluster moved on without it. Because of that, it will continue acting as if it is the current controller. This is a common scenario in distributed systems and is called split-brain.
Let’s go through an example. Imagine the active controller really does go into a long stop-the-world GC pause. Its ZooKeeper session expires and /controller znode it registered is now deleted. Every other broker in the cluster is notified of this as they placed ZooKeeper Watches on it.
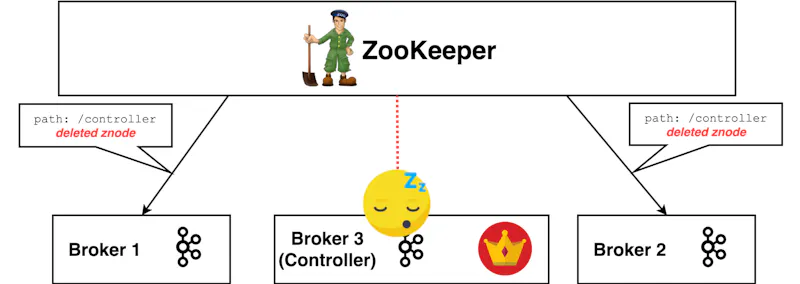
To fix the controller-less cluster, every broker now tries to become the new controller itself. Let’s say Broker 2 won the race and became the new controller by creating the /controller znode first.
Every broker receives a notification that this znode was created and now knows who the latest leader is — Broker 2. Every broker except Broker 3, which is still in a GC pause. It is possible that this notification does not reach it for one reason or another (e.g OS has too many accepted connections awaiting processing and drops it). In the end, the information about the leadership change does not reach Broker 3.
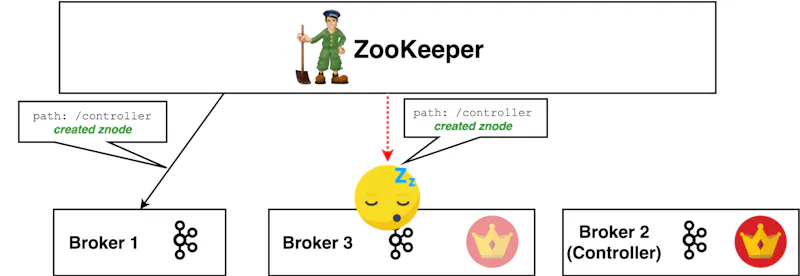
Broker 3’s garbage collection pause will eventually finish and it will wake up still thinking it is in charge. Remember, nothing has changed through its eyes.

You now have two controllers which will be giving out potentially conflicting commands in parallel. This is something you do not want in your cluster. If not handled, it can result in critical failures.
If Broker 2 (new controller node) receives a request from Broker 3, how will it know whether Broker 3 is the newest controller or not? For all Broker 2 knows, the same GC pause might have happened to it too!
There needs to be a way to distinguish who the real, current controller of the cluster is.
There is such a way! It is done through the use of an epoch number (also called a fencing token). An epoch number is simply a monotonically increasing number — if the old leader had an epoch number of 1, the new one will have 2. Brokers can now easily differentiate the real controller by simply trusting the controller with the highest number. The controller with the highest number is surely the latest one, since the epoch number is always-increasing. This epoch number is stored in ZooKeeper.
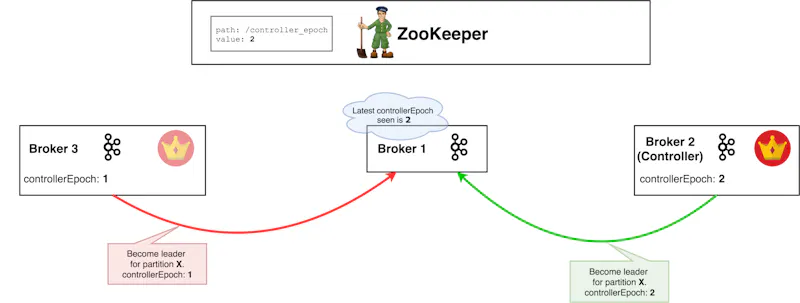
Here, Broker 1 stores the latest controllerEpoch it has seen and ignores all requests from controllers with a previous epoch number.
Let’s look at the Kafka code directly from the source
def registerControllerAndIncrementControllerEpoch(controllerId: Int): (Int, Int) = {
val timestamp = time.milliseconds()
// Read /controller_epoch to get the current controller epoch and zkVersion,
// create /controller_epoch with initial value if not exists
val (curEpoch, curEpochZkVersion) = getControllerEpoch
.map(e => (e._1, e._2.getVersion))
.getOrElse(maybeCreateControllerEpochZNode())
// Create /controller and update /controller_epoch atomically
val newControllerEpoch = curEpoch + 1
val expectedControllerEpochZkVersion = curEpochZkVersion
debug(s"Try to create ${ControllerZNode.path} and increment controller epoch to
$newControllerEpoch with expected controller epoch zkVersion $expectedControllerEpochZkVersion")
def checkControllerAndEpoch(): (Int, Int) = {
val curControllerId = getControllerId.getOrElse(throw new ControllerMovedException(
s"The ephemeral node at ${ControllerZNode.path} went away while checking
whether the controller election succeeds. Aborting controller startup procedure"))
if (controllerId == curControllerId) {
val (epoch, stat) = getControllerEpoch.getOrElse(
throw new IllegalStateException(s"${ControllerEpochZNode.path} existed before
but goes away while trying to read it"))
// If the epoch is the same as newControllerEpoch, it is safe to infer that the
// returned epoch zkVersion is associated with the current broker during
// controller election because we already knew that the zk
// transaction succeeds based on the controller znode verification. Other rounds of controller
// election will result in larger epoch number written in zk.
if (epoch == newControllerEpoch)
return (newControllerEpoch, stat.getVersion)
}
throw new ControllerMovedException("Controller moved to another broker.
Aborting controller startup procedure")
}
def tryCreateControllerZNodeAndIncrementEpoch(): (Int, Int) = {
val response = retryRequestUntilConnected(
MultiRequest(Seq(
CreateOp(ControllerZNode.path, ControllerZNode.encode(controllerId, timestamp),
defaultAcls(ControllerZNode.path), CreateMode.EPHEMERAL),
SetDataOp(ControllerEpochZNode.path, ControllerEpochZNode.encode(newControllerEpoch),
expectedControllerEpochZkVersion)))
)
response.resultCode match {
case Code.NODEEXISTS | Code.BADVERSION => checkControllerAndEpoch()
case Code.OK =>
val setDataResult = response.zkOpResults(1).rawOpResult.asInstanceOf[SetDataResult]
(newControllerEpoch, setDataResult.getStat.getVersion)
case code => throw KeeperException.create(code)
}
}
tryCreateControllerZNodeAndIncrementEpoch()
}
private def maybeCreateControllerEpochZNode(): (Int, Int) = {
createControllerEpochRaw(KafkaController.InitialControllerEpoch).resultCode match {
case Code.OK =>
info(s"Successfully created ${ControllerEpochZNode.path} with initial epoch ${KafkaController.InitialControllerEpoch}")
(KafkaController.InitialControllerEpoch, KafkaController.InitialControllerEpochZkVersion)
case Code.NODEEXISTS =>
val (epoch, stat) = getControllerEpoch.getOrElse(throw new IllegalStateException(s"${ControllerEpochZNode.path} existed before but goes away while trying to read it"))
(epoch, stat.getVersion)
case code =>
throw KeeperException.create(code)
}
def getControllerEpoch: Option[(Int, Stat)] = {
val getDataRequest = GetDataRequest(ControllerEpochZNode.path)
val getDataResponse = retryRequestUntilConnected(getDataRequest)
getDataResponse.resultCode match {
case Code.OK =>
val epoch = ControllerEpochZNode.decode(getDataResponse.data)
Option(epoch, getDataResponse.stat)
case Code.NONODE => None
case _ => throw getDataResponse.resultException.get
}
}
Key Implementation Details
Atomic Operations
tryCreateControllerZNodeAndIncrementEpoch() method handles two critical operations atomically using ZooKeeper's MultiRequest to execute both operations atomically. Either both succeed or both fail.
Creating a controller znode indicating this broker is the controller
CreateOp()Incrementing the controller epoch to prevent split-brain scenarios
SetDataOp()
Optimistic Concurrency
SetDataOp() in tryCreateControllerZNodeAndIncrementEpoch() uses the ZooKeeper version number (expectedControllerEpochZkVersion) to ensure that the epoch is only updated if no one else has modified it since it was read - this is a classic example of optimistic updates.
Ephemeral Nodes
The controller znode is created as an ephemeral node (CreateMode.EPHEMERAL), which means it will be automatically deleted if the controller broker's ZooKeeper session expires - critical for automatic failure detection.
Takeaways
If you have read so far, I appreciate your patience. Hope you learnt something new today and Thank you for reading.
To support exactly once execution — performing Leader Election or taking a locks isn’t enough — there should be additional checks at the time of task execution to detect whether it’s safe to actually execute the task. Fencing Token is one such way — however generating one isn’t so straightforward.
Please feel free to ask any questions you might have in the comments.